![]()

Runtime -> Change runtime type and set hardware type to GPU.Introduction
Last time we built a sentiment classifier with scikit-learn and achieved around 85% accuracy on the test set. This is already pretty good, but can we do better? We are still wrong 15/100 times. It turns out we can if we use deep learning.

Deep learning uses an architecture that is modeled after the brain and uses networks of artificial neurons to mimic its behaviour. These models are much bigger than the models we encountered so far and can have millions to billions of parameters. Training these models and adjusting the parameters is also more challenging, and generally requires much more data and compute. A lot of computations are easily parallelizable, which is a strength of modern GPUs. Therefore we will run this notebook on a GPU that enables much faster training than a CPU.

Since we don't have much training data on the IMDb dataset for deep learning standards we use transfer learning to still achieve high accuracy in predicting the sentiment of the movie reviews.
Transfer learning
Training deep learning models requires a lot of data. It is not uncommon to train models on millions of images or gigabytes of text data to achieve good results. Most real-world problems don't have that amount of labeled data ready, and not all companies or individuals who want to train a model can afford to hire people to label data for them.
For many years this has been very challenging. Fortunately, it has been solved for image based models a couple of years ago and recently also for NLP. One approach that helps train models with limited labeled data is called transfer learning.
The idea is that once a model is trained on a large dataset for a specific task (e.g., classifying houses vs. planes), the model has learned certain features of the data that can be reused for another task. Such features could be how to detect edges or textures in images. If these features are useful for another task, then we can train the model on new data without requiring as many labels as if we were training it from scratch.
Language modeling
In language modeling the goal is to predict the next word based on the previous word in a text. An example:
Yesterday I discovered a really nice cinema so I went there to watch a ____ .
The task of the model is to fill the blank. The advantage of language modeling is that it does not require any labels, but to achieve good results, the model needs to learn a lot about language. In this example, the model needs to understand that one watches movies in cinemas. The same goes for sentiment and other topics. With ULMFiT one can train a language model and then use it for classifications tasks in three steps.
Three steps
The three steps are visualised in the following figure:
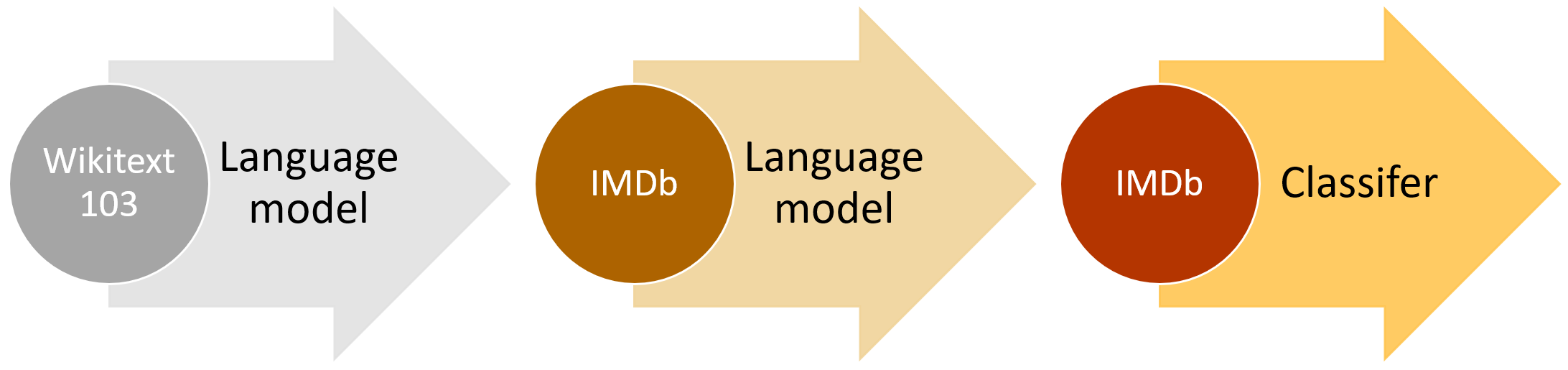
Language model (wiki): A language model is trained on a large dataset. Wikipedia is a common choice for this task as it includes many topics, and the text is of high quality. This step usually takes the most time on the order of days. In this step, the model learns the general structure of language.
Language model (domain): The language model trained on Wikipedia might be missing some aspects of the domain we are interested in. If we want to do sentiment classification, Wikipedia does not offer much insight since Wikipedia articles are generally of neutral sentiment. Therefore, we continue training the language model on the text we are interested in. This step still takes several hours.
Classifier (domain): Now that the language model works well on the text we are interested in, it is time to build a classifier. We do this by adapting the output of the network to yield classes instead of words. This step only takes a couple of minutes to an hour to complete.
The power of this approach is that you only need little labeled data for the last step and only need to go through the expensive first step once. Even the second step can be reused on the dataset if you, for example, build a sentiment classifier and additionally a topic classifier. This can be done in minutes and allows us to achieve great results with little time and resources.
The fastai library
The fastai library wraps around the deep learning framework PyTorch and has a lot of functionality built in to achieve great results quickly. The library abstracts a lot of functionality, so it can be difficult to follow initially. To get a better understanding, we highly recommend the fastai course. In this lesson, we will use the library to build a world-class classifier with just a few lines of code.
!pip install dslectures
from fastai.text import *
from dslectures.core import get_dataset
path = untar_data(URLs.IMDB)
Data structure
Looking at the downloaded folder, we can see that there are several files and folders. The relevant ones for our case are test, train, and unsup. The train and test folders split the data the same way we split it in the previous lecture. The new unsup (for unsupervised) folder contains 50k movie reviews that are not classified. We can't use them for training a classifier, but we can use them to fine-tune the language model.
path.ls()
Looking at the training folder, we find two folders for the negative and positive movie reviews.
(path/'train/').ls()
In both folders, we find many files, each containing one movie review. This is exactly the same data we used last time. It is just arranged in a different structure. We don't need to load all these files manually - the fastai library does this automatically.
(path/'train/neg').ls()[:10]
Preprocess data for language modeling
In the last lecture, we implemented our own function to preprocess the texts and tokenize them. In principle, we could do the same here, but fastai comes with built-in functions to take care of this. In addtion, we can specify which folders to use and what percentage to split off for validation. The batch size bs specifies how many samples the model is optimised for at each step.
bs=48
data_lm = (TextList.from_folder(path)
#Inputs: all the text files in path
.filter_by_folder(include=['train', 'test', 'unsup'])
#We may have other temp folders that contain text files so we only keep what's in train and test
.split_by_rand_pct(0.1)
#We randomly split and keep 10% (10,000 reviews) for validation
.label_for_lm()
#We want to do a language model so we label accordingly
.databunch(bs=bs))
Similar to the vectorizer vocabulary, we can have a look at the encoding scheme. The itos (stands for id-to-string) object tells us which token is encoded at which position.
len(data_lm.vocab.itos)
We can see that the vocabulary contains XXX tokens.
data_lm.vocab.itos[:20]
We can see that the first few positions are reserved for special tokens starting with xx. The token xxunk is used for a word that is not in the dictionary. The xxbos and xxeos identify the beginning and the end of a string. So if the first entry in the encoding vector is 1 this means that the token is xxunk. If the third entry is 1 then the token is xxbos.
We can also look at a processed text. We notice that the token xxmaj is used frequently. It signifies that the first letter of the following word is capitalised.
data_lm.train_ds[0][0]
With fastai we can also sample a batch from the dataset and display the sample in a dataframe:
data_lm.show_batch()
Representation
When we vectorized the texts in the last lecture, we represented them as count vectors. The architecture we use in this lecture allows for each word to be processed sequentially and thus conserving the order information. Therefore we encode the text with one-hot encodings. However, storing the information as vectors would not be very memory efficient; one entry is 1 and all the other entries are 0. It is more efficient to just store the information on which entry is 1 and then create the vector when we need it.
We can look at the data representation of the example we printed above. Each number represents a word in the vocabulary and specifies the entry in the one-hot encoding that is set to one.
data_lm.train_ds[0][0].data[:10]
With the itos we can translate it back to tokens:
for i in data_lm.train_ds[0][0].data[:10]:
print(data_lm.vocab.itos[i])
Train model
We will train a variant of a model called LSTM (long short-term memory) network. This is a neural network with a feedback loop. That means that when fed a sequence of tokens, it feeds back its output for the next prediction. With this the model has a mechanism remembering the past inputs. This is especially useful when dealing with sequential data such as texts, where the sequence of words and characters carries important meaning.
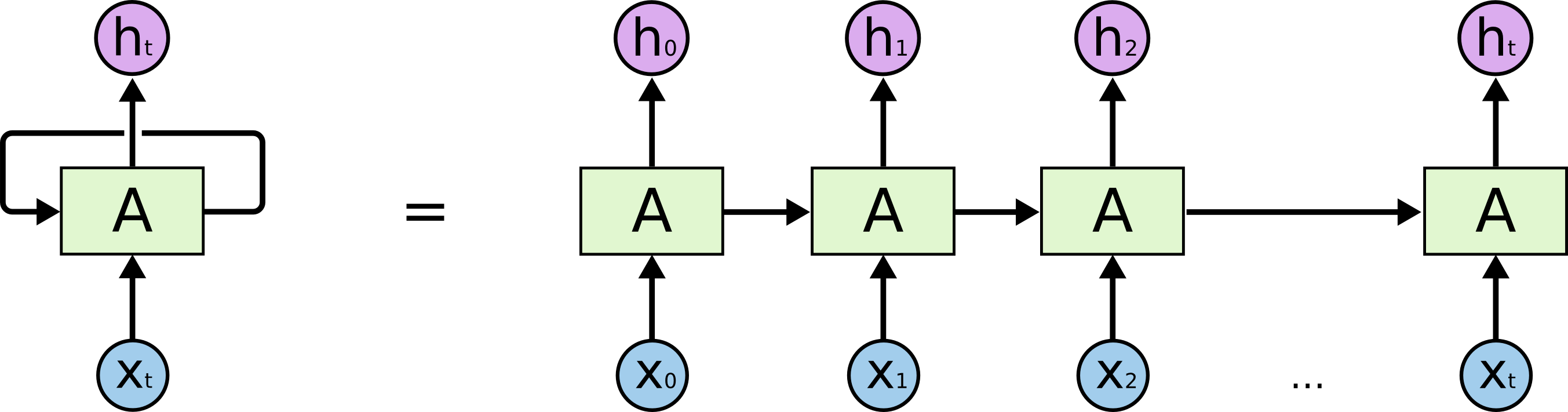
Reference: https://colah.github.io/posts/2015-08-Understanding-LSTMs/
learn = language_model_learner(data_lm, AWD_LSTM, drop_mult=0.3, model_dir="../data/")
Learning rate finder
The learning rate is a key parameter when training models in deep learning. It specifies how strongly we update the model parameters. If the learning rate is too small, the training takes forever. If the learning rate is too big, we will never converge to a minimum.
With the lr_find() function, we can explore how the loss function behaves with regards to the value of the learning rate:
learn.lr_find()
learn.recorder.plot(skip_end=15)

First of all, we see that if we choose the learning rate too big, the loss function starts to increase. We want to avoid this at all costs. So we want to find the spot where the loss function decreases the steepest with the largest learning rate. In this case, a good value is 1e-2. The first parameter determines how many epochs we train. One epoch corresponds to one pass through the training set.
learn.fit_one_cycle(1, 1e-2, moms=(0.8,0.7))
Deep learning models learn more and more abstractions with each layer. The first layers of an image model might learn about edges and textures in an image, and as you progress through the layers, you can see how the model combines edges to eyes or ears and eventually combines these to faces. Therefore the last few layers are usually the ones that are very task-specific while the others contain general information.
For this reason, we usually start by just tuning the last few layers because we don't want to lose that information and then, in the end, fine-tune the whole model. This is what we did above: we just trained the last few layers. Now to get the best possible performance, we want to train the whole model. The unfreeze() function enables the training of the whole model. We train the model for 10 more epochs with a slightly lower learning rate.
learn.unfreeze()
learn.fit_one_cycle(10, 1e-3, moms=(0.8,0.7))
# uncomment if you want to fine-tune the language mode
# data_lm.path = Path('')
# data_lm.save('data_lm.pkl')
# learn.save('fine_tuned')
get_dataset("fine_tuned.pth")
get_dataset("data_lm.pkl")
data_lm = load_data(Path("../data/"), 'data_lm.pkl', bs=bs)
data_lm.path = path
learn = language_model_learner(data_lm, AWD_LSTM, drop_mult=0.3, model_dir="../data/")
learn.path = Path("")
learn.load('fine_tuned');
learn.path = path
TEXT = "I liked this movie because"
N_WORDS = 40
N_SENTENCES = 2
print("\n".join(learn.predict(TEXT, N_WORDS, temperature=0.75) for _ in range(N_SENTENCES)))
Encoder
As mentioned previously, the last layers of a deep learning model are usually the most task-specific. In the case of language modeling, the last layer predicts the next word in a sequence. We want to do text classification, however, so we don't need that layer. Therefore, we discard the last layer and only save what is called the encoder. In the next step, we add a new layer on top of the encoder for text classification.
learn.save_encoder('fine_tuned_enc')
data_clas = (TextList.from_folder(path, vocab=data_lm.vocab)
#grab all the text files in path
.split_by_folder(valid='test')
#split by train and valid folder (that only keeps 'train' and 'test' so no need to filter)
.label_from_folder(classes=['neg', 'pos'])
#label them all with their folders
.databunch(bs=bs))
When we display a batch we see that the tokens look the same with the addition of a label column:
data_clas.show_batch()
learn = text_classifier_learner(data_clas, AWD_LSTM, drop_mult=0.5, model_dir="../data/")
learn.load_encoder('fine_tuned_enc');
learn.lr_find()
learn.recorder.plot()

learn.fit_one_cycle(1, 2e-2, moms=(0.8,0.7))
Then we unfreeze the second to last layer as well and train these layers.
learn.freeze_to(-2)
learn.fit_one_cycle(1, slice(1e-2/(2.6**4),1e-2), moms=(0.8,0.7))
Next, we train the last three layers.
learn.freeze_to(-3)
learn.fit_one_cycle(1, slice(5e-3/(2.6**4),5e-3), moms=(0.8,0.7))
Finally, we train all layers for two epochs.
learn.unfreeze()
learn.fit_one_cycle(2, slice(1e-3/(2.6**4),1e-3), moms=(0.8,0.7))
Note that after the last optimisation step the model can predict the sentiment on the test set with 94% accuracy. This is roughly 10% better than our Naïve Bayes model from the last lecture. In other words, this model makes 3 times fewer mistakes than the Naïve Bayes model!
learn.predict("I really loved that movie, it was awesome!")