![]()
![]()
References
- Persistent Homology: A Non-Mathy Introduction with Examples by G. Koplik
- Chapter 2 of An Introduction to Topological Data Analysis for Physicists: From LGM to FRBs by J. Murugan and D. Robertson
- Getting Started with giotto-tda by L. Tunstall et al
- A Topological “Reading” Lesson: Classification of MNIST using TDA by A. Garin and G. Tauzin

In general terms, persistent homology focuses on answering the question
As one increases a threshold, at what scale do we observe changes in some geometric representation of the data?
The answer to this question involves deep mathematics and will not be covered here. Instead we wil focus on introducing the main concepts that are needed to extract topologial features from data, and how these features can be combined with machine learning algorithms.

It turns out that persistent homology is well suited for detecting structure in high dimensional datasets, so it is no surprise that the technique has mostly been applied in cosmology to either constrain non-Gaussianity in the CMB or find cosmic voids or filament loops in the large-scale structure of matter. Persistent homology does not appear to have been used in particle physics, so perhaps the time is ripe for the enterprising graduate student 🤓!
%load_ext autoreload
%autoreload 2
# uncomment this if running locally or on Google Colab
# !pip install --upgrade hepml
# data wrangling
import numpy as np
import pandas as pd
from pathlib import Path
import pickle
from typing import List
from PIL import Image
from hepml.core import download_dataset
from scipy import ndimage
# tda magic
from gtda.homology import VietorisRipsPersistence, CubicalPersistence
from gtda.diagrams import PersistenceEntropy
from gtda.plotting import plot_heatmap, plot_point_cloud, plot_diagram
from gtda.pipeline import Pipeline
from hepml.core import make_point_clouds, load_shapes
# ml tools
from sklearn.ensemble import RandomForestClassifier
from sklearn.preprocessing import LabelEncoder
# dataviz
import matplotlib.pyplot as plt
In this lesson we will be using point cloud data and images to calculate topological features. The code below downloads both the raw data along with some precomputed NumPy arrays so that you can skip some of the time-consuming tasks on Binder / Colab:
# 3D shapes
download_dataset("shapes.zip")
# diagrams for circles, spheres, tori
download_dataset("diagrams_basic.pkl")
# diagrams for real-world objects
download_dataset("diagrams.pkl")
# computer vision
download_dataset("Cells.jpg")
download_dataset("BlackHole.jpg")
DATA = Path('../data/')
# uncomment to unzip the shapes folder
# !unzip {DATA}/'shapes.zip' -d {DATA}

Figure reference: https://pythonawesome.com/semantic-and-instance-segmentation-of-lidar-point-clouds-for-autonomous-driving/
Techniques for analyzing 3D shapes are becoming increasingly important due to the vast number of sensors such as LiDAR that are capturing 3D data, as well as numerous computer graphics applications. These raw data are typically collected in the form of a point cloud, which corresponds to a set of 3D points $\{p_i | i = 1, \ldots, n\}$, where each point $p_i$ is a vector of its $(x, y, z)$ coordinates plus extra feature channels such as color, intensity etc. Typically Euclidean distance is used to calculate the distances between any two points.
By finding suitable representations of these point clouds, machine learning can be used to solve a variety of tasks such as those shown in the figure below.
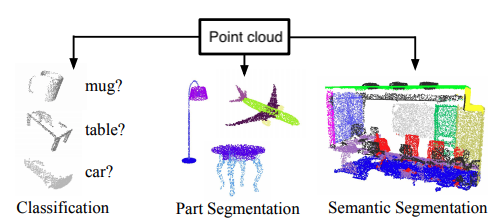
Figure reference: adapted from https://arxiv.org/abs/1612.00593
In this section we will examine how topological features can be extracted from point cloud data and fed to a simple classifier to distinguish 3D shapes.
point_clouds_basic, labels_basic = make_point_clouds(n_samples_per_shape=10, n_points=20, noise=0.5)
point_clouds_basic.shape, labels_basic.shape
Here the labels are defined to that a circle is 0, a sphere is 1, and a torus is 2. Each point cloud corresponds to a sampling of the continuous surface - in this case 400 points are sampled per shape. As a sanity check, let's visualise these points clouds:
# expect circle
plot_point_cloud(point_clouds_basic[0])
# expect sphere
plot_point_cloud(point_clouds_basic[10])
# expect torus
plot_point_cloud(point_clouds_basic[-1])
From data to persistence diagrams
In raw form, point cloud data is not well suited for most machine learning algorithms because we ultimately need a feature matrix $X$ where each row corresponds to a single sample (i.e. point cloud) and each column corresponds to a particular feature. In our example, each point cloud corresponds to a collection of 3-dimensional vectors, so we need some way of representing this information in terms of a single vector $x^{(i)}$ of feature values.
In this lesson we will use persistent homology to generate a topological summary of a point cloud in the form of a so-called persistence diagram. Perhaps the simplest way to understand persistent homology is in terms of growing balls around each point. The basic idea is that by keeping track of when the balls intersect we can quantify when topological features like connected components and loops are "born" or "die".
For example, consider two noisy clusters and track their connectivity or "0-dimensional persistent homology" as we increase the radius of the balls around each point:
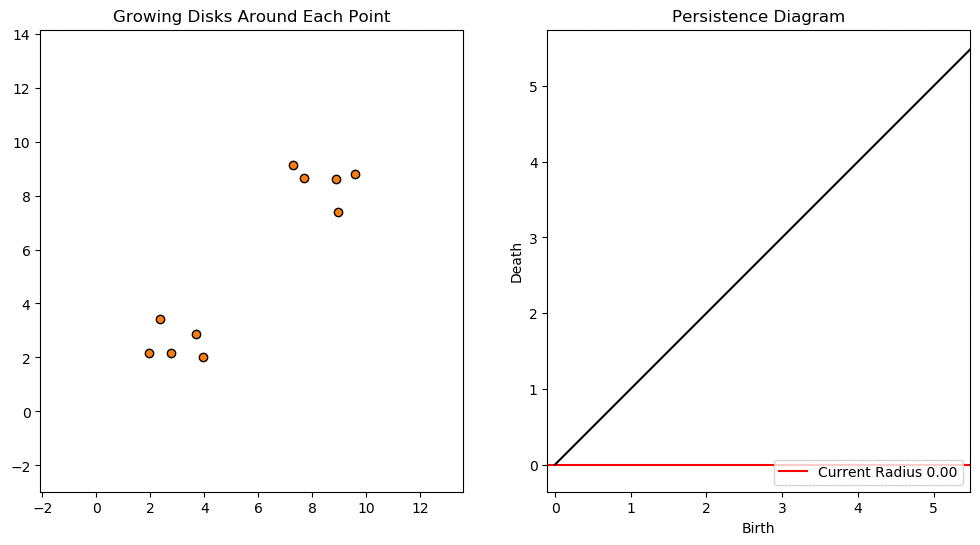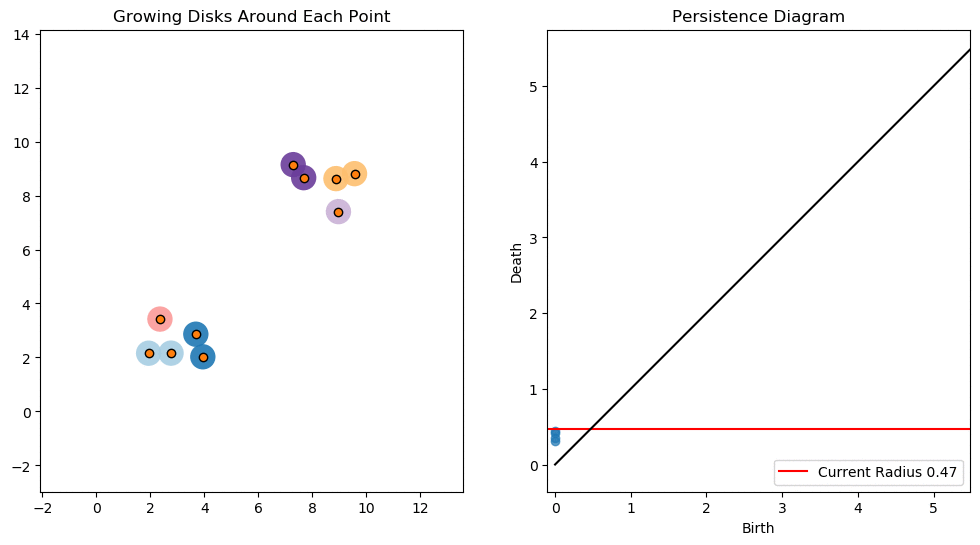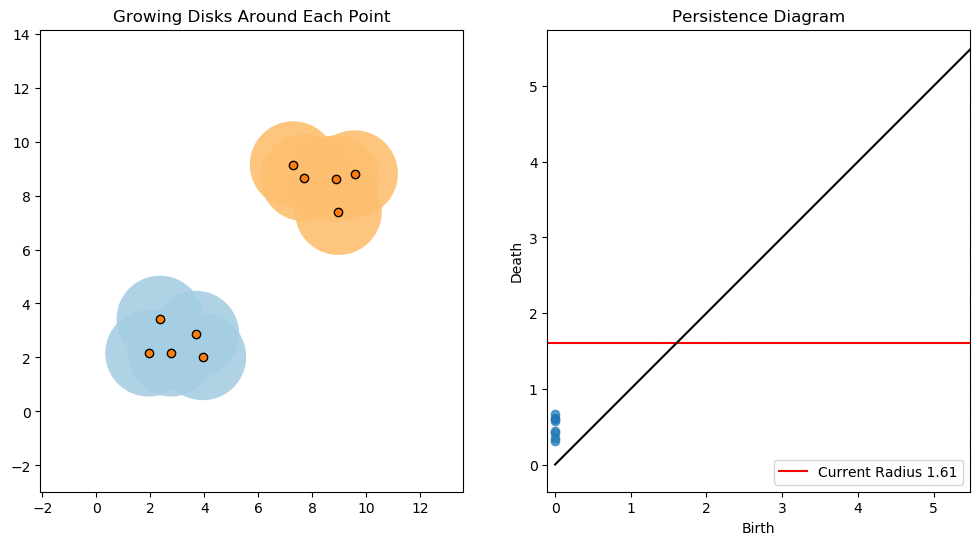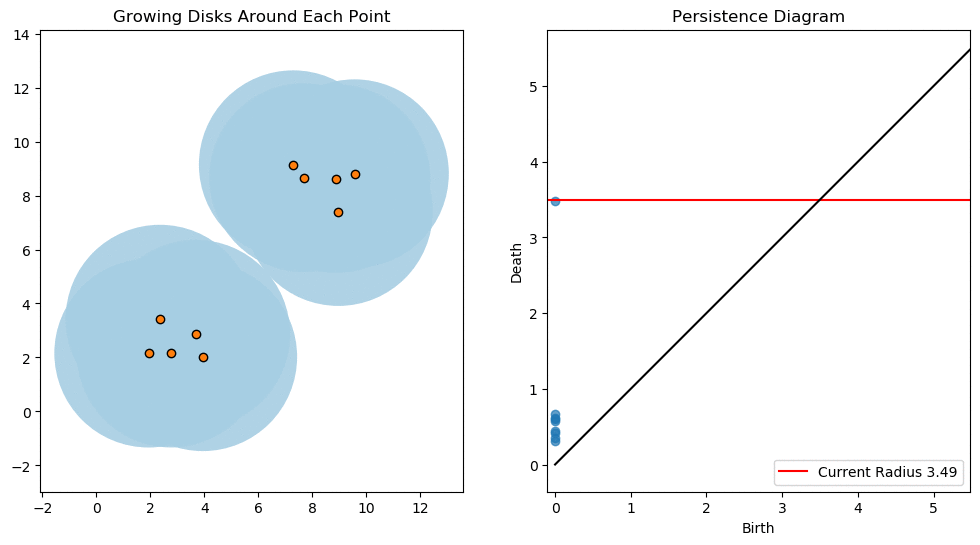
Figure reference: https://towardsdatascience.com/persistent-homology-with-examples-1974d4b9c3d0
As the ball radius is grown from 0 to infinity, 0-dimensional persistent homology records when the ball in one connected component first intersects a ball of a different connected component (denoted by a different colour in the animation). At radius 0, a connected component for each point is born and once any two balls touch we have a death of a connected component with one color persisting and the other color vanishing. Each color vanishing corresponds to a death and therefore another point being added to the persistence diagram.
Behind the scenes, this process generating a persistent diagram from data involves several steps:
The effect of connecting points as we increase some radius $\epsilon$ results in the creation of geometric objects called simplices.
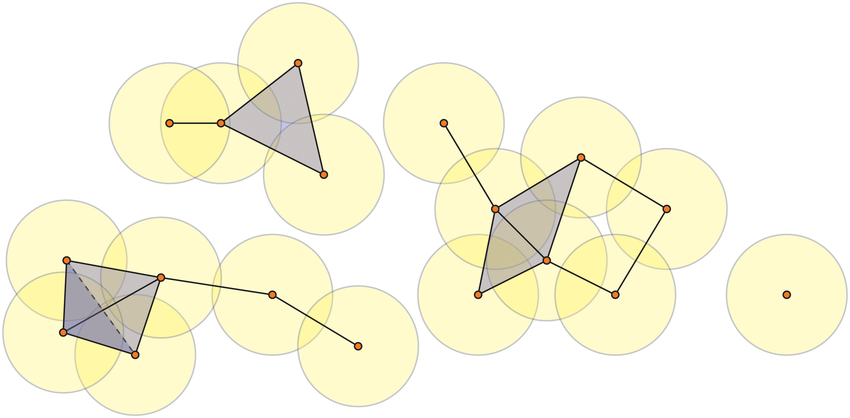
Figure reference: https://bit.ly/2z9yP1d
A $k$-simplex is a set of $k+1$ vertices, so for example the 0-simplex is a point, the 1-simplex is a line, the 2-simplex is a triangular disc, and a 3-simplex a regular tetrahedron:
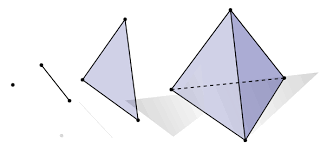
Figure reference: https://bit.ly/2X8AsUX
Linking simplices together results in a simplicial complex, with a $k$-complex defined as a geometric simplicial complex containing at least one $k$ simplex, and with no simplices of dimension strictly greater than $k$. For example, the image below shows a 3-complex:
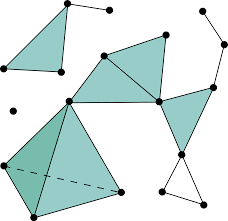
Figure reference: https://en.wikipedia.org/wiki/Simplicial_complex
One of the most common complexes is the Vietoris-Rips complex, which is defined as the simplicial complex whose $k$-simplices are all subsets of $\{p_0,\ldots p_k\} \subseteq M$ with distance metric $d(p_i,p_j) \leq \epsilon \,\, \forall i,j$.
Once the simplicial complex is constructed, we can ask questions about its topology. In particular, we can identify the presence of topological invariants such as connected pieces, holes and voids. This is achieved by computing quantities known as Betti numbers which are informally defined as follows:
The $k$th Betti number refers to the number of $k$-dimensional holes on a topological surface. The first few Betti numbers have the following definitions for 0-dimensional, 1-dimensional, and 2-dimensional simplicial complexes:> > * $b_0$ is the number of connected components
- $b_1$ is the number of one-dimensional or "circular" holes
- $b_2$ is the number of two-dimensional "voids" or "cavities"
By computing Betti numbers of a range of scale values $\epsilon$, we can track which topological features persist over this range. We can represent these changes in topology (technically homology) in terms of a persistent diagram, where each point corresponds to (birth, death) pairs, and points which are furthest away from the birth = death line correspond to the most persistent features.
An example showing the birth and death of "loops" (technically the homology group $H_1$) is shown below.
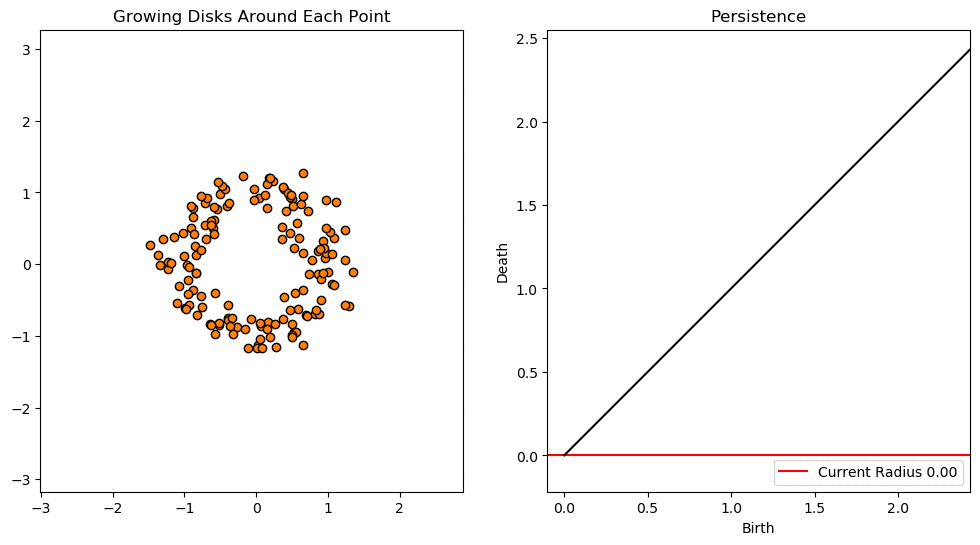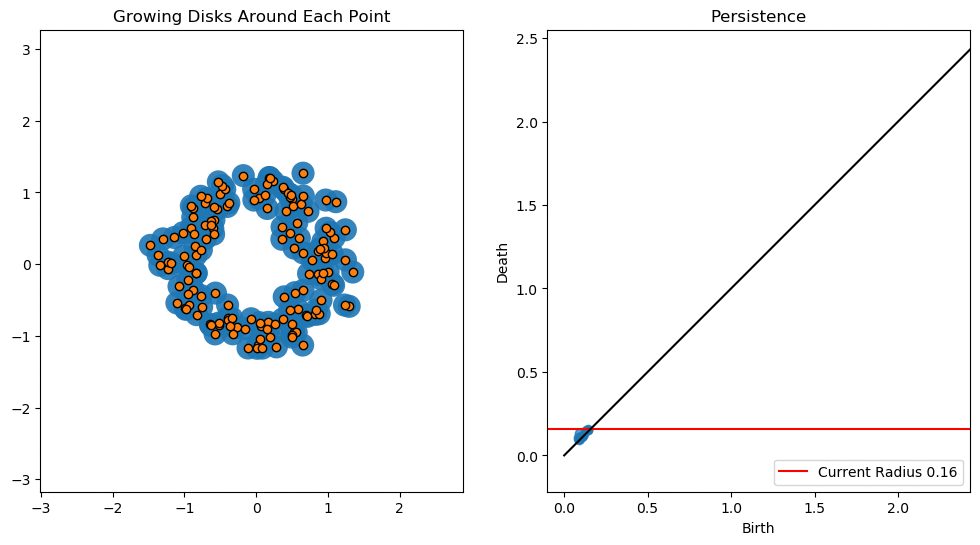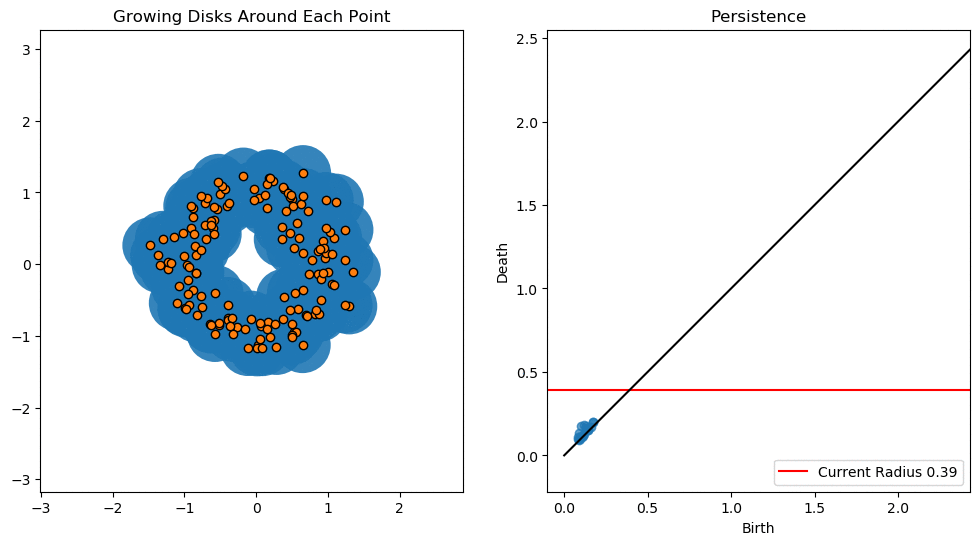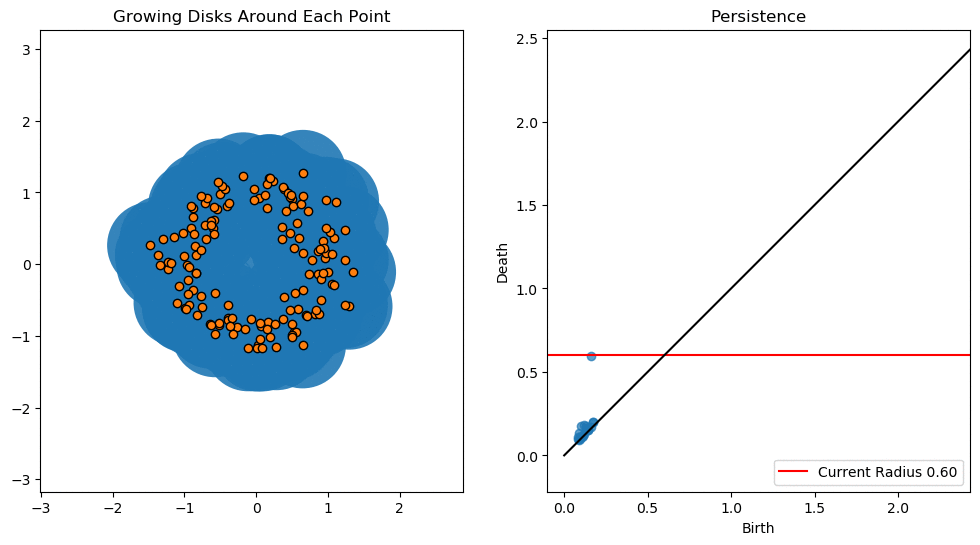
Figure reference: https://towardsdatascience.com/persistent-homology-with-examples-1974d4b9c3d0
Let's descend from abstraction and apply these concepts to our shape classification problem! In giotto-tda we can derive persistent diagrams from data by selecting the desired transformer in gtda.homology and instantiating the class just like a scikit-learn estimator. Once the transformer is instantiated, we can make use of the fit-transform paradigm to generate the diagrams:
# track connected components, loops, and voids
homology_dimensions = [0, 1, 2]
# calculating H2 persistence is memory intensive - see below to use precomputed arrays
persistence = VietorisRipsPersistence(metric="euclidean", homology_dimensions=homology_dimensions, n_jobs=6)
%time diagrams_basic = persistence.fit_transform(point_clouds_basic)
Since calculating persistent diagrams is often one of the most time consuming parts in the pipeline, it is a good idea to save our intermediate results to disk:
DATA = Path("../data")
with open(DATA / "diagrams_basic.pkl", "wb") as f:
pickle.dump(diagrams_basic, f)
We can then load our diagrams from disk as follows:
with open(DATA / "diagrams_basic.pkl", "rb") as f:
diagrams_basic = pickle.load(f)
diagrams_basic.shape
Once we have computed our persistence diagrams, we can compare how the circle, sphere and torus produce different patterns at each homology dimension:
# circle
plot_diagram(diagrams_basic[0])
# sphere
plot_diagram(diagrams_basic[10])
# torus
plot_diagram(diagrams_basic[-1])
From the persistence diagrams we can see which persistent generators $H_{1,2,3}$ are most persistent for each shape. In particular, we see that:
- the circle has one persistent generator $H_1$ corresponding to a loop
- the sphere has one persistent generator $H_2$ corresponding to a void
- the torus has three persistent generators, two for $H_1$ and one for $H_2$
Although persistence diagrams are useful descriptors of the data, they cannot be used directly for machine learning applications. This is because different persistence diagrams may have different numbers of points, and basic operations like the addition and multiplication of diagrams are not well-defined.
To overcome these limitations, a variety of proposals have been made to “vectorise” persistence diagrams via embeddings or kernels which are well-suited for machine learning. In giotto-tda, we provide access to the most common vectorisations via the gtda.diagrams module.
For example, one such feature is known as persistent entropy which measures the entropy of points in a diagram $D = \{(b_i, d_i)\}_{i\in I}$ according to
$$ E(D) = - \sum_{i\in I} p_i \log p_i$$
where $p_i =(d_i - b_i)/L_D$ and $L_D = \sum_i (d_i - b_i)$. As we did for the persistent diagram calculation, we can use a transformer to calculate the persistent entropy associated with each homology generator $H_{0,1,2}$:
persistent_entropy = PersistenceEntropy()
# calculate topological feature matrix
X_basic = persistent_entropy.fit_transform(diagrams_basic)
# expect shape - (n_point_clouds, n_homology_dims)
X_basic.shape
Nice - we have found a way to represent each point cloud in terms of just three numbers! Note that this does not depend on the number of points in the original point cloud, although calculating the $H_2$ generators becomes time consuming for point clouds of $O(10^3)$ points (at least on a standard laptop).
By visualising the feature matrix
plot_point_cloud(X_basic)
we see that there are three distinct clusters, suggesting that a classifier should have no trouble finding a clean decision boundary!
With our topological features at hand, the last step is to train a classifier. Since our dataset is small, we will use a Random Forest and make use of the OOB score to simulate accuracy on a validation set:
rf = RandomForestClassifier(oob_score=True)
rf.fit(X_basic, labels_basic)
print(f"OOB score: {rf.oob_score_:.3f}")
Unsurprisingly, our classifier has perfectly separated the 3 classes. Next let's try a slightly more realistic example.
Evidently, there are several data transformation steps that need to be executed in the right order to go from point clouds to predictions. Fortunately giotto-tda provides a Pipeline class to collect such sequences of transformations. Below is a small pipeline that reproduces all our steps:
steps = [
("persistence", VietorisRipsPersistence(metric="euclidean", homology_dimensions=[0, 1], n_jobs=6)),
("entropy", PersistenceEntropy()),
("model", RandomForestClassifier(oob_score=True)),
]
pipeline = Pipeline(steps)
By calling the fit method, the pipeline calls fit_transform on all transformers before calling fit on the final estimator:
pipeline.fit(point_clouds_basic, labels_basic)
We can then access the Random Forest model by its key model to pick out the OOB score:
pipeline["model"].oob_score_
In the above example, the shapes were sufficiently distinct that it was easy to classify them according to their topological features. Here we consider a slightly more realistic example using point clouds from a variety of real-world objects. We will use the 3D dataset from Princeton's COS 429 Computer Vision course. The dataset consists of 200 models organised into 20 classes of 10 objects each:
classes = [
"biplane",
"desk_chair",
"dining_chair",
"fighter_jet",
"fish",
"flying_bird",
"guitar",
"handgun",
"head",
"helicopter",
"human",
"human_arms_out",
"potted_plant",
"race_car",
"sedan",
"shelves",
"ship",
"sword",
"table",
"vase",
]To load the data, let's create a simple function to select which subset of classes we'd like to analyse:
SHAPES = Path("../data/shapes")
df = load_shapes(SHAPES, ["human_arms_out", "vase", "dining_chair", "biplane"], 400)
df.head()
As a sanity check, let's filter our pandas.DataFrame for a single member of a class, e.g. a biplane:
# use DataFrame.values to conver to NumPy array
plot_point_cloud(df.query('label == "biplane0"')[["x", "y", "z"]].values)
Next, let's collect all these point clouds in a single NumPy array:
# use @ symbol to reference local variables in f-string
point_clouds = np.asarray([df.query("label == @shape")[["x", "y", "z"]].values for shape in df["label"].unique()])
point_clouds.shape
As we did with the simple shapes, we can calculate persistence diagrams for each of these point clouds:
# track connected components, loops, and voids
homology_dimensions = [0, 1, 2]
# calculating H2 persistence is memory intensive - see below to use precomputed arrays
persistence = VietorisRipsPersistence(metric="euclidean", homology_dimensions=homology_dimensions, n_jobs=6)
%time persistence_diagrams = persistence.fit_transform(point_clouds)
with open(DATA / "diagrams.pkl", "wb") as f:
pickle.dump(persistence_diagrams, f)
with open(DATA / "diagrams.pkl", "rb") as f:
diagrams = pickle.load(f)
By zooming in on the resulting diagrams, we can spot some persistent generators, but with far less signal than before:
# index - (human_arms_out, 0), (vase, 10), (dining_chair, 20), (biplane, 30)
index = 0
plot_diagram(diagrams[20])
Next we convert each diagram into a 3-dimensional vector using persistent entropy and plot the resulting feature matrix:
persistent_entropy = PersistenceEntropy()
# calculate topological feature matrix
X = persistent_entropy.fit_transform(diagrams)
# expect shape - (n_point_clouds, n_dims)
X.shape
plot_point_cloud(X)
Unlike our simple shapes example, we do not see distinct clusters so we expect our classifier performance to be less than perfect in this case. Before we can train a model, we need to define a target vector for each point cloud. A crude, but simple way is to label each class with an integer starting from 0 to $n_\mathrm{classes} - 1$:
labels = np.zeros(40)
labels[10:20] = 1
labels[20:30] = 2
labels[30:] = 3
rf = RandomForestClassifier(oob_score=True, random_state=42)
rf.fit(X, labels)
# score
rf.oob_score_
Persistent homology can also be used to study images by treating the pixels as a point cloud in Euclidean space. However, in this case it is better to use so-called cubical complexes instead of Vietoris-Rips, as the former can exploit the grid-like structure of images. As the name suggests, a cubical complex is built from cubes instead of simplices. The following examples are adapted from C. Tralie's TDALabs repository.
As a warmup, let's create a synthetic "image" involving 3 negative Gaussians:
ts = np.linspace(-1, 1, 100)
x1 = np.exp(-(ts ** 2) / (0.1 ** 2))
ts -= 0.4
x2 = np.exp(-(ts ** 2) / (0.1 ** 2))
# create image
img = -x1[None, :] * x1[:, None] - 2 * x1[None, :] * x2[:, None] - 3 * x2[None, :] * x2[:, None]
# plot image
plt.imshow(img)
plt.colorbar()
plt.show()

As noted here, a greyscale image comes equipped with a natural filtration on the values of its pixels. In particular, one can define a filtration of cubical complexes that are ordered by the intensity or greyscale value. So to apply cubical persistence in giotto-tda we need to pass a greyscale image so let's simply rescale the points in our Gaussian blobs to lie in the interval $[0, 255]$ where 0 is dark and 255 is bright:
img_scaled = 255 * (img - np.min(img)) / (np.max(img) - np.min(img))
plt.imshow(img_scaled)
plt.colorbar()
plt.show()

This "image" is now suitable for generating persistence diagrams from, and we can generate the plot in one go as follows:
# reshape input array to be (n_samples, n_pixels_x, n_pixels_y)
CubicalPersistence(homology_dimensions=[0]).fit_transform_plot(img_scaled[None, :, :]);
From this simple example, we see that are 3 dots corresponding to each of the 3 Gaussians.
Next, let's look at the famous image of a black hole silloutte:
bh_original = plt.imread(DATA/'BlackHole.jpg')
bh_grey = np.asarray(Image.fromarray(bh_original).convert("L"))
def plot_images(original, greyscale):
fig, (ax0, ax1) = plt.subplots(ncols=2, figsize=(10,10))
ax0.set_title(f"Image shape: {original.shape}")
ax0.imshow(original)
ax0.axis('off')
ax1.set_title(f"Image shape: {greyscale.shape}")
ax1.imshow(greyscale, cmap='gray')
ax1.axis('off')
plt.show()
plot_images(bh_original, bh_grey)

As before, we can pass our greyscale image and calculate the persistence diagram:
CubicalPersistence(homology_dimensions=[0, 1]).fit_transform_plot(bh_grey[None, :, :]);
Nice, we've just confirmed that a black hole actually has a hole!
One interesting application of cubical persistence concerns image segmentation. Consider for example an image of wood cells, with a blurred counterpart to encourage the segmentation to focus on more robust features:
cells_original = plt.imread(DATA/"Cells.jpg")
cells_grey = np.asarray(Image.fromarray(cells_original).convert("L"))
cells_blurred = -ndimage.uniform_filter(cells_grey.astype(np.float64), size=10)
cells_blurred += 0.01 * np.random.randn(*cells_blurred.shape)
plot_images(cells_original, cells_blurred)

As before we can calculate the persistence diagram as usual:
dgm = CubicalPersistence(homology_dimensions=[0]).fit_transform(cells_blurred[None, :, :])
but will plot the lifetime vs birth for reasons that will shortly become clear:
plt.scatter(dgm[0][:, 0], dgm[0][:, 1] - dgm[0][:, 0])
plt.xlabel('Birth')
plt.ylabel('Lifetime')
plt.show()

thresh = 70
idxs = np.arange(dgm[0].shape[0])
idxs = idxs[np.abs(dgm[0][:, 1] - dgm[0][:, 0]) > thresh]
plt.figure(figsize=(8, 5))
plt.imshow(cells_original)
X, Y = np.meshgrid(np.arange(cells_blurred.shape[1]), np.arange(cells_blurred.shape[0]))
X = X.flatten()
Y = Y.flatten()
for idx in idxs:
bidx = np.argmin(np.abs(-cells_blurred + dgm[0][idx, 0]))
plt.scatter(X[bidx], Y[bidx], 20, "k")
plt.axis("off")
plt.show()

Not bad! With only two tunable parameters (blurring and threshold) we have managed to get excellent performance in a fully unsupervised manner!
Exercises
- Experiment with the shapes dataset to see whether including the amplitude of persistent diagrams improves performance compared to persistent entropy alone. You may also want to compare how the performance is affected according to each homology class, i.e. building a classifier with just the persistent entropies for $H_0$ vs $H_1$ vs $H_2$.
- Pick an image of your choosing and see if you can extract topological features from it using the techniques in this notebook.
- Advanced: try to reproduce the results from the paper where
giotto-tdawas used to classify hand-written digits: https://arxiv.org/pdf/1910.08345.pdf. Note this is not trivial, but would be a very instructive experience!