![]()
![]()
- Understand how to go from simple to complex models
- Understand the concepts of bagging and out-of-bag score
- Gain an introduction to hyperparameter tuning
- Understand how to interpret permutation feature importance plots for Random Forest models.
- Chapters 6 & 7 of Hands-On Machine Learning with Scikit-Learn and TensorFlow by Aurèlien Geron
- Beware Default Random Forest Feature Importances
- Searching for exotic particles in high-energy physics with deep learning by Baldi et al.
The data
We will continue our analysis of the SUSY dataset from lesson 1, but this time start from our prepared training and test sets:
susy_train.feathersusy_test.feather
By using the Feather format we can load our data in a fraction of the time compared to CSV.
# reload modules before executing user code
%load_ext autoreload
# reload all modules every time before executing Python code
%autoreload 2
# render plots in notebook
%matplotlib inline
# uncomment this if running locally or on Google Colab
# !pip install --upgrade hepml
# data wrangling
import pandas as pd
import numpy as np
from scipy import stats
from pathlib import Path
from hepml.core import display_large, download_dataset
# data viz
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.metrics import plot_roc_curve, plot_confusion_matrix
from sklearn.tree import plot_tree
sns.set(color_codes=True)
sns.set_palette(sns.color_palette("muted"))
# ml magic
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, roc_auc_score
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import RandomizedSearchCV
from sklearn.inspection import permutation_importance
import scipy
from scipy.cluster import hierarchy as hc
As usual, we can download our datasets by using our download_dataset helper function:
download_dataset("susy_train.feather")
download_dataset("susy_test.feather")
We also make use of the pathlib library to handle our filepaths:
DATA = Path("../data")
!ls {DATA}
With pathlib it is a simple matter to define the filepath to the dataset, and since the file is in Feather format we can load it as a pandas.DataFrame as follows:
susy_train = pd.read_feather(DATA / "susy_train.feather")
susy_train.head()
susy_train.shape
susy_test = pd.read_feather(DATA / "susy_test.feather")
susy_test.head()
susy_test.shape
As a sanity check, let's see create our sample and see how our baseline model performs on the validation set:
# you may want to reduce this to 20,000 if running on Binder / Colab
susy_sample = susy_train.sample(n=100000, random_state=42)
X = susy_sample.drop("signal", axis=1)
y = susy_sample["signal"]
X_train, X_valid, y_train, y_valid = train_test_split(
X, y, test_size=0.2, random_state=42
)
print(f"Dataset split: {len(X_train)} train rows + {len(X_valid)} valid rows")
model = RandomForestClassifier(n_estimators=10, n_jobs=-1, random_state=42)
%time model.fit(X_train, y_train)
def print_scores(fitted_model):
res = {
"Accuracy on train:": accuracy_score(fitted_model.predict(X_train), y_train),
"ROC AUC on train:": roc_auc_score(
y_train, fitted_model.predict_proba(X_train)[:, 1]
),
"Accuracy on valid:": accuracy_score(fitted_model.predict(X_valid), y_valid),
"ROC AUC on valid:": roc_auc_score(
y_valid, fitted_model.predict_proba(X_valid)[:, 1]
),
}
if hasattr(fitted_model, "oob_score_"):
res["OOB accuracy:"] = fitted_model.oob_score_
for k, v in res.items():
print(k, round(v, 3))
print_scores(model)
As we found in lesson 1, this simple model achieves a ROC AUC score of 0.84 and falls short of the benchmark models by a few percent (see table):
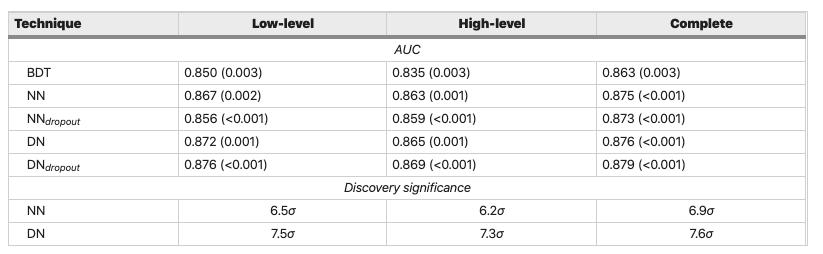
Figure reference: https://www.nature.com/articles/ncomms5308
Let's build a model that is so simple that we can actually take a look at it. As we saw in lesson 1, a Random Forest is simply a forest of decision trees, so let's begin by looking at a single tree (called estimators in scikit-learn):
model = RandomForestClassifier(
n_estimators=1, max_depth=3, bootstrap=False, n_jobs=-1, random_state=42
)
model.fit(X_train, y_train)
In the above we have fixed the following hyperparameters:
n_estimators = 1: create a forest with one tree, i.e. a decision treemax_depth = 3: how deep or the number of "levels" in the treebootstrap = False: this setting ensures we use the whole dataset to build the treen_jobs = -1: this parallelises the computation over all CPU coresrandom_state = 42: this sets the random seed so our results are reproducible
Let's see how this simple model performs:
print_scores(model)
Unsurprisingly, this single tree yields worse predictions (ROC AUC 0.779) than our baseline with 10 trees (ROC AUC 0.840). Nevertheless, we can visualise the tree by accessing the estimators_ attribute and making use of scikit-learn's plotting API (link):
# get column names
feature_names = X_train.columns
# define class names
class_names = ["Background", "Signal"]
# we need to specify the background color because of a quirk in sklearn
fig, ax = plt.subplots(figsize=(30, 10), facecolor="k")
# generate tree plot
plot_tree(
model.estimators_[0],
filled=True,
feature_names=feature_names,
class_names=class_names,
ax=ax,
fontsize=18,
)
plt.show()

From the figure we observe that a tree consists of a sequence of binary decisions, where each box includes information about:
- The binary split criterion (mean squared error (mse) in this case)
- The number of
samplesin each node. Note we start with the full dataset in the root node and get successively smaller values at each split. - Darker blues (oranges) indicate a higher amount of signal (background) events in the
valueattribute - The best single binary split is for
M_TR_2 <= 1.162which reduces the Gini impurity from 0.496 in the root node to 0.438 (0.323) in the depth-1 left (right) node.
Right now our simple tree model has an accuracy of 74.2% on the validation set - let's try to make better by removing the max_depth=3 restriction:
model = RandomForestClassifier(
n_estimators=1, bootstrap=False, n_jobs=-1, random_state=42
)
model.fit(X_train, y_train)
print_scores(model)
Note that removing the max_depth constraint has yielded perfect accuracy and ROC AUC scores on the training set! That is because in this case each leaf node has exactly one element, so we can perfectly segment the data. We also have an accuracy of ROC AUC score of 0.708 on the validation set which is worse than our shallow tree, so let's look at some techniques to improve it.
Bagging is a technique that can be used to improve the ability of models to generalise to new data.
The basic idea between bagging is to consider training several models, each of which is only partially predictive, but crucially, uncorrelated. Since these models are effectively gaining different insights into the data, by averaging their predictions we can create an ensemble that is more predictive!
As shown in the figure, bagging is a two-step process:
- Bootstrapping, i.e. sampling the training set
- Aggregation, i.e. averaging predictions from multiple models
This gives us the acronym Bootstrap AGGregatING, or bagging for short 🤓.
The key for this to work is to ensure the errors of each mode are uncorrelated, so the way we do that with trees is to sample with replacement from the data: this produces a set of independent samples upon which we can train our models for the ensemble.
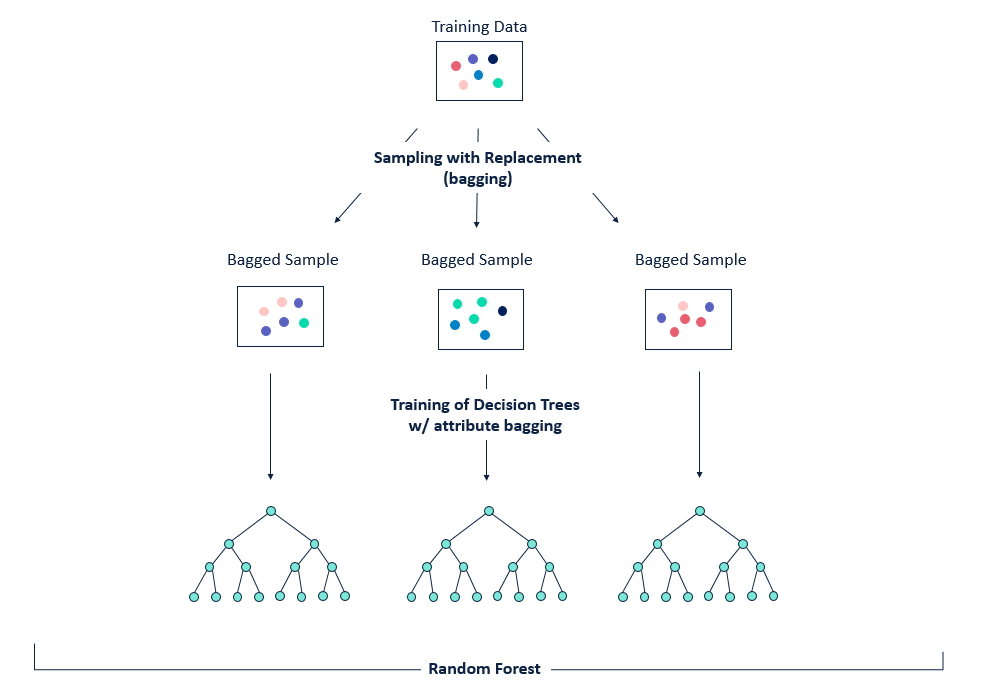
Figure reference: https://bit.ly/33tGPVT
If we revisit our very first model, we saw that the number of trees (n_estimators) is one of the parameters we can tune when building our Random Forest. Let's look at this more closely and see how the performance of the forest improves as we add trees.
model = RandomForestClassifier(n_estimators=10, n_jobs=-1, random_state=42)
model.fit(X_train, y_train)
After training, each tree is stored in an attribute called estimators_. For each tree, we can call predict() on the validation set and use the numpy.stack() function to concatenate the predictions together:
preds = np.stack([tree.predict_proba(X_valid)[:,1] for tree in model.estimators_])
Since we have 10 trees and 20,000 samples in our validation set, we expect that preds will have shape $(n_\mathrm{trees}, n_\mathrm{samples})$:
Let's now look at a plot of the AUC score as we increase the number of trees:
def plot_auc_vs_trees(preds, y_valid):
"""Generate a plot of accuracy on validation set vs number of trees in Random Forest"""
fig, ax = plt.subplots()
plt.plot(
[
roc_auc_score(y_valid, np.mean(preds[: i + 1], axis=0))
for i in range(len(preds) + 1)
]
)
ax.set_ylabel("Accuracy on validation set")
ax.set_xlabel("Number of trees")
plot_auc_vs_trees(preds, y_valid)

As we add more trees, the AUC score improves but appears to flatten out. Let's test this numerically.
for n_estimators in [20, 40, 80, 160]:
print(f"Number of trees: {n_estimators}\n")
model = RandomForestClassifier(
n_estimators=n_estimators, n_jobs=-1, random_state=42
)
model.fit(X_train, y_train)
print_scores(model)
print("=" * 50, "\n")
preds = np.stack([tree.predict_proba(X_valid)[:,1] for tree in model.estimators_])
plot_auc_vs_trees(preds, y_valid)

Adding more trees slows the computation down, so we can conclude from the plot that about 80 trees is a good number to gain good performance for cheaper compute.
So far, we've been using a validation set to examine the effect of tuning hyperparameters like the number of trees - what happens if the dataset is small and it may not be feasible to create a validation set because you would not have enough data to build a good model? Random Forests have a nice feature called Out-Of-Bag (OOB) error which is designed for just this case!
The key idea is to observe that the first tree of our ensemble was trained on a bagged sample of the full dataset, so if we evaluate this model on the remaining samples we have effectively created a validation set per tree. To generate OOB predictions, we can then calculate the majority class of all the trees and calculate ROC AUC, accuracy, or whatever metric we are interested in.
To toggle this behaviour in scikit-learn, one makes use of the oob_score flag, which adds an oob_score_ attribute to our model that we can print out:
model = RandomForestClassifier(
n_estimators=80, n_jobs=-1, oob_score=True, random_state=42
)
model.fit(X_train, y_train)
print_scores(model)
Let's look at a few more hyperparameters that can be tuned in a Random Forest.
The hyperparameter min_samples_leaf controls whether or not the tree should continue splitting a given node based on the number of samples in that node. By default, min_samples_leaf = 1, so each tree will split all the way down to a single sample, but in practice it can be useful to work with values 3, 5, 10, 25 and see if the performance improves.
for leaf_val in [1, 3, 5, 10, 25]:
print(f"Leaf value: {leaf_val}", "\n")
model = RandomForestClassifier(
n_estimators=80, min_samples_leaf=leaf_val, n_jobs=-1, random_state=42,
)
model.fit(X_train, y_train)
print_scores(model)
print("=" * 50, "\n")
For this particular dataset, setting min_samples_leaf = 25 improves our metrics on the validation set, so let's fix this parameter to that value.
Another good hyperparameter to tune is max_features, which controls what random number or fraction of columns we consider when making a single split at a tree node. Here, the motivation is that we might have situations where a few columns in our data are highly predictive, so each tree will be biased towards picking the same splits and thus reduce the generalisation power of our ensemble. To counteract that, we can tune max_features, where good values to try are 1.0, 0.5, log2, or sqrt.
for max_feat in [0.5, 1.0, "log2", "sqrt"]:
print(f"Max features: {max_feat}", "\n")
model = RandomForestClassifier(
n_estimators=80,
min_samples_leaf=25,
max_features=max_feat,
n_jobs=-1,
random_state=42,
)
model.fit(X_train, y_train)
print_scores(model)
print("=" * 50, "\n")
Going beyond the default setting of max_features = 'sqrt' does not appear to help much. Nevertheless, compared to our first naive model with just 10 trees and default settings, this model achieves a ROC AUC of 0.87 on the validation set - an improvement of around 4.5%! This improvement may not sound like much, but in practice these incremental improvements can translate into high impact when aggregated over many such decisions (e.g. for event processing).
Training a model that accurately predicts outcomes is great, but most of the time you don't just need predictions, you want to be able to interpret your model. To work out which features are most important for a model's predictions, scikit-learn provides a clever technique known as permutation feature importance:
The permutation feature importance is defined to be the decrease in a model score when a single feature value is randomly shuffled 1. This procedure breaks the relationship between the feature and the target, thus the drop in the model score is indicative of how much the model depends on the feature. This technique benefits from being model agnostic and can be calculated many times with different permutations of the feature.
model = RandomForestClassifier(
n_estimators=80,
min_samples_leaf=25,
max_features="sqrt",
n_jobs=-1,
random_state=42,
)
model.fit(X_train, y_train)
result = permutation_importance(
model, X_valid, y_valid, n_repeats=10, random_state=42, n_jobs=-1, scoring="roc_auc"
)
sorted_idx = result.importances_mean.argsort()
fig, ax = plt.subplots(figsize=(12, 8))
ax.boxplot(
result.importances[sorted_idx].T, vert=False, labels=X_valid.columns[sorted_idx]
)
ax.set_title("Permutation Importance (validation set)")
fig.tight_layout()
plt.show()

From the plot we see the important features are a mix of the eight kinematic features, as well as ten hand-crafted features based on physics intuition.
Consistent with the physics of these supersymmetric decays in the lepton channel, we find that the most informative features for classification are the:
- missing energy magnitude due to the neutralino
- the transverse momentum $p_T$ of one of the charged leptons
- missing transverse energy along the vector defined by the charged leptons (Axial MET) and
In our analysis above we manually inspected how the performance evolved when we changed the hyperparameters of the Random Forest one at a time. In practice, it can be better to automate this process using scikit-learn's RandomizedSearchCV to search for the best combination of hyperparameter values:
# define range of values for each hyperparameter
param_dist = [
{
"n_estimators": [10, 20, 40, 80, 160],
"max_features": [0.5, 1.0, "sqrt", "log2"],
"min_samples_leaf": [1, 5, 10, 25],
}
]
# instantiate baseline model
model = RandomForestClassifier(n_estimators=10, n_jobs=-1)
# initialise random search with cross-validation
random_search = RandomizedSearchCV(
model, param_distributions=param_dist, cv=5, scoring="roc_auc", n_jobs=-1
)
# this is a RAM hungry monster, so best fed on a laptop!
%time random_search.fit(X, y)
Once the search is finished, we can get the best combination of parameters as follows:
random_search.best_params_
We can also examine the evaluation scores as follows:
cv_results = random_search.cv_results_
for score, params in zip(cv_results["mean_test_score"], cv_results["params"]):
print(f"{score:.3f}", params)
Now that we've tweaked our model's parameters, let's evaluate the final model on the test set. Here we just need the best model, and to evaluate it's predictions on the test set:
# select best model from randomised search
best_model = random_search.best_estimator_
# define features and target for test set
X_test, y_test = susy_test.drop("signal", axis=1), susy_test["signal"]
# calculate probabilities per class
probs = best_model.predict_proba(X_test)[:, 1]
# evaluate against ground truth
roc_auc_score(y_test, probs)
The performance is compatible with that on the validation set, which suggests we have managed to not overfit! Compared to the benchmark models in the original article, our model is now better than the Boosted Decision Tree and with 0.5-1% of the (deep) neural networks - not bad!
- Use the techniques in this lesson to build Random Forest models for the "low-level" and "high-level" set of features. How do their ROC AUC scores compare against the table above?
- Randomised search is not guaranteed to find the best set of hyperparameters, so for an exhaustive search one should use grid search. To reduce the computational overhead, use the results from randomised search to reduce the parameter space and then launch a grid search to select the optimal features within this space.
- Use the optimal features either from randomised or grid search to train a Random Forest from scratch on the whole training set
susy_trainand evaluate its predictions onsusy_test. You may want to increasen_estimatorsto get slightly higher performance. With 4.5 million events to train on, this step is best done with the computational resources of your desktop or laptop!