![]()
![]()
References
- Sliding Windows and Persistence: An Application of Topological Methods to Signal Analysis by J. Perea and J.Harer
- The sliding window notebooks from C. Tralie's TDALabs
- Detection of gravitational waves using topological data analysis and convolutional neural network: An improved approach by C. Bresten and J.H.Jung. We thank C. Bresten for sharing the code and data used in the article.
In time series analysis it is common to represent the signal of interest as a real-valued function over some bounded domain $I$ that represents time:
$$ f: I \to \mathbb{R}$$
One of the most important tasks in time series analysis is the ability to make predictions, e.g. given the Amazon stock price now, what will be the price in one week? One way to tackle this question is to identify recurrent patterns in $f$. The goal of this lesson is to show how one can use tools from topological data analysis to answer these type of questions.
Let's see a preview of how this might work. Given a positive real number $\tau$ and a positive integer $M$, the sliding window embedding of $f$ with parameters $(M,\tau)$ is the function
$$ SW_{M,\tau} f : \mathbb{R} \to \mathbb{R}^{M+1}\,, \qquad t \to \begin{bmatrix} f(t) \\ f(t + \tau) \\ f(t + 2\tau) \\ \vdots \\ f(t + M\tau) \end{bmatrix} $$The main idea we will explore in this notebook is that if $f$ has a non-trivial recurrent structure, then the image of $SW_{M,\tau}f$ will have non-trivial topology for appropriate choices of $(M, \tau)$.
%load_ext autoreload
%autoreload 2
# uncomment this if running locally or on Google Colab
# !pip install --upgrade hepml
# data wrangling
import numpy as np
import pandas as pd
from pathlib import Path
from IPython.display import YouTubeVideo
from fastprogress import progress_bar
# hepml
from hepml.core import make_gravitational_waves, download_dataset
# tda magic
from gtda.homology import VietorisRipsPersistence, CubicalPersistence
from gtda.diagrams import PersistenceEntropy, Scaler
from gtda.plotting import plot_heatmap, plot_point_cloud, plot_diagram
from gtda.pipeline import Pipeline
from gtda.time_series import TakensEmbedding
# ml tools
from sklearn.ensemble import RandomForestClassifier
from sklearn.decomposition import PCA
from sklearn.model_selection import train_test_split
from sklearn.metrics import plot_roc_curve, roc_auc_score, accuracy_score
# dataviz
import matplotlib.pyplot as plt
import seaborn as sns
sns.set(color_codes=True)
sns.set_palette(sns.color_palette("muted"))
The first step in analysing the topology of time series is to construct a so-called sliding window embedding, invented by Takens in the 1960s. As shown in the diagram below, a sliding window embedding of a signal can be thought of as sliding a "window" of fixed size over a signal, with each window represented as a point in a (possibly) higher-dimensional space:
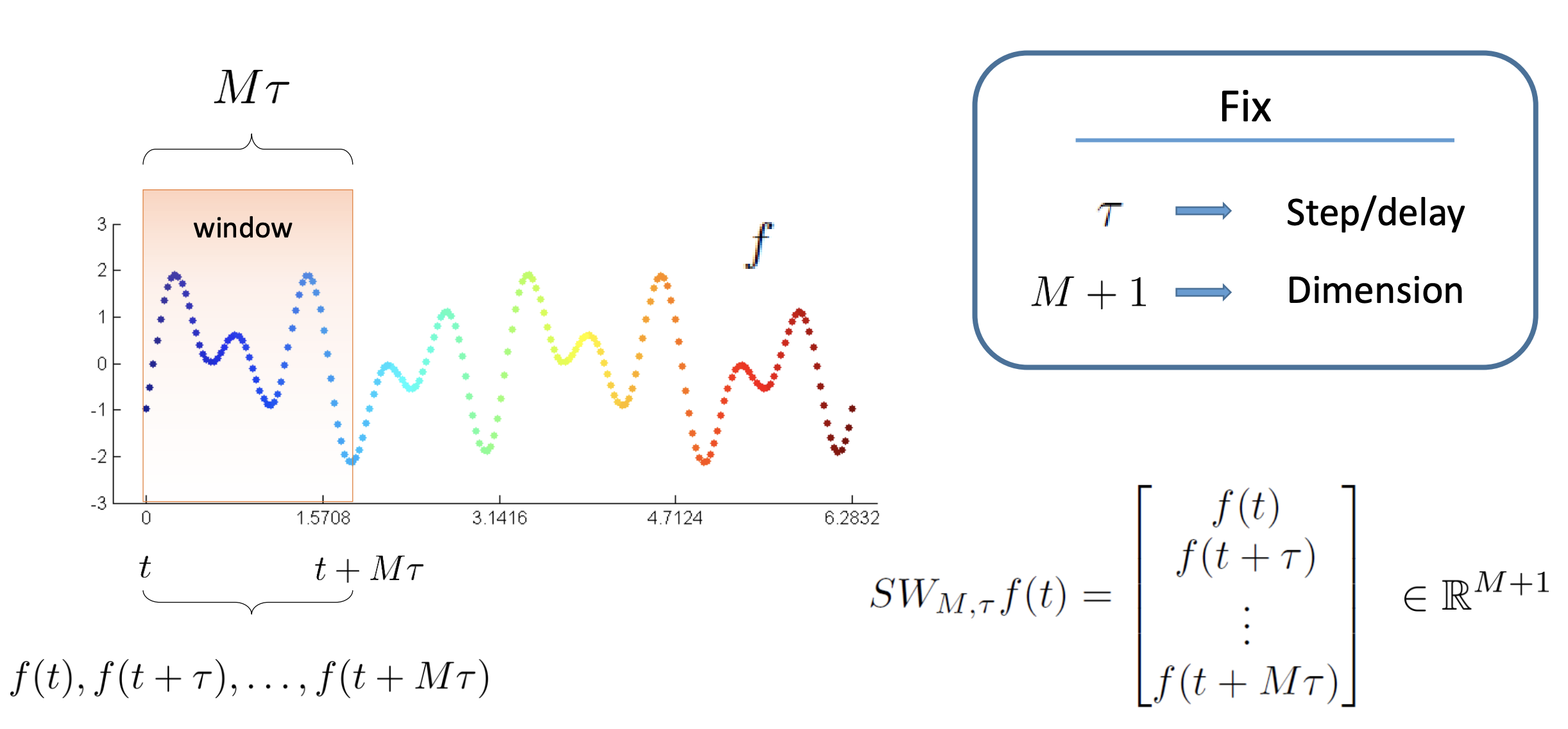
Figure reference: https://bit.ly/3easx09
More formally: given a time series $f(t)$, one can extract a sequence of vectors of the form $f_i = [(f(t_i)), f(t_i + 2 \tau), \ldots, f(t_i + M \tau)] \in \mathbb{R}^{M+1}$, where $M$ is the embedding dimension and $\tau$ is the time delay. The quantity $M\tau$ is known as the "window size" and the difference between $t_{i+1}$ and $t_i$ is called the stride.
The sliding window allows us to apply Takens' embedding locally on a certain interval rather than over the whole time series. The result of this procedure is a time series of point clouds with possibly interesting topologies. These topologies can be used to classify whether a signal is periodic or not.
As a warm-up, recall that a function is periodic with period $T > 0$ if $f(t + T) = f(t)$ for all $t \in \mathbb{R}$. For example, consider the function $f(t) = \cos(5 t)$ which can be visualised as follows:
x_periodic = np.linspace(0, 10, 1000)
y_periodic = np.cos(5 * x_periodic)
print(f"Number of time steps: {len(y_periodic)}")
plt.figure(figsize=(20, 4))
plt.plot(x_periodic, y_periodic)
plt.xlabel("Timestep")
plt.ylabel("Amplitude")
plt.show()

We can show that periodicity implies circularity of the sliding window embedding. To do that we need to specify the embedding dimension $M$ and the time delay $\tau$ for the Takens embedding:
embedding_dimension_periodic = 3
embedding_time_delay_periodic = 8
stride = 10
embedder_periodic = TakensEmbedding(
parameters_type="fixed",
n_jobs=2,
time_delay=embedding_time_delay_periodic,
dimension=embedding_dimension_periodic,
stride=stride,
)
stride parameter to downsample the sliding window embedding. This is handy when you want to quickly compute persistence diagrams on a dense signal.Let's apply this embedding to our time series to get a new time series:
y_periodic_embedded = embedder_periodic.fit_transform(y_periodic)
y_periodic_embedded.shape
We have gone from a one-dimensional series to a 3-dimensional one, so let's visualise the sliding window embedding as a point cloud:
plot_point_cloud(y_periodic_embedded)
As promised, the periodicity of $f$ is reflected in the circularity of the sliding window embedding! It turns out that in general, periodic functions trace out ellipses in $\mathbb{R}^{M+1}$.
Here is another type of recurrent behaviour: if we let $f(t) = \cos(t) + \cos(\pi t)$ then it follows that $f$ is not periodic since the ratio of the two frequencies is irrational, i.e. we say that $\cos(t)$ and $\cos(\pi t)$ are incommensurate. Nevertheless, their sum produces recurrent behaviour:
x_nonperiodic = np.linspace(0, 50, 1000)
y_nonperiodic = np.cos(x_nonperiodic) + np.cos(np.pi * x_nonperiodic)
print(f"Number of time steps: {len(y_nonperiodic)}")
plt.figure(figsize=(8, 4))
plt.plot(x_nonperiodic, y_nonperiodic)
plt.xlabel("Amplitude")
plt.ylabel("Timestep")
plt.show()

As before, let's create a sliding window embedding for this signal and visualise the resulting point cloud:
embedding_dimension_nonperiodic = 3
embedding_time_delay_nonperiodic = 16
stride = 3
embedder_nonperiodic = TakensEmbedding(
parameters_type="fixed",
n_jobs=2,
time_delay=embedding_time_delay_nonperiodic,
dimension=embedding_dimension_nonperiodic,
stride=stride,
)
y_nonperiodic_embedded = embedder_nonperiodic.fit_transform(y_nonperiodic)
y_nonperiodic_embedded.shape
plot_point_cloud(y_nonperiodic_embedded)
In the examples above we saw that the resulting point clouds appear to exhibit distinct topology. We can verify this explicitly using persistent homology! First we need to reshape our point cloud arrays in a form suitable for the Vietoris-Rips construction, namely (n_samples, n_points, n_dimensions):
y_periodic_embedded = y_periodic_embedded[None, :, :]
y_nonperiodic_embedded = y_nonperiodic_embedded[None, :, :]
# check shapes
y_periodic_embedded.shape, y_nonperiodic_embedded.shape
The next step is to calculate the persistence diagrams associated with each point cloud:
homology_dimensions = [0, 1, 2]
periodic_persistence = VietorisRipsPersistence(homology_dimensions=homology_dimensions, n_jobs=6)
%time periodic_persistence_diagrams = periodic_persistence.fit_transform(y_periodic_embedded)
nonperiodic_persistence = VietorisRipsPersistence(homology_dimensions=homology_dimensions, n_jobs=6)
%time nonperiodic_persistence_diagrams = nonperiodic_persistence.fit_transform(y_nonperiodic_embedded)
Let's now compare the two diagrams, first for the periodic signal:
plot_diagram(periodic_persistence_diagrams[0])
and next for the non-periodic one:
plot_diagram(nonperiodic_persistence_diagrams[0])
What can conclude from these diagrams? The first thing that stands out is the different types of homology dimensions that are most persistent. In the periodic case we see a single point associated with 1-dimensional persistent homology, namely a loop! On the other hand, the non-periodic signal has revealed two points associated with 2-dimensional peristent homology, namely voids. These clear differences in topology make the sliding window embedding technique especially powerful at classifying different time series.
In the examples above, we manually chose values for the embedding dimension $M$ and time delay $\tau$. However, it turns out there are two techniques that can be used to determine these parameters automatically:
- Mutual information to determine $\tau$
- False nearest neighbours to determine $M$
In giotto-tda, these techniques are applied when we select parameters_type="search" in the TakensEmbedding transformer, e.g.
embedder = TakensEmbedding(
parameters_type="search", time_delay=time_delay, dimension=embedding_dimension,
)
where the values of time_delay and embedding_dimension provide upper bounds on the search algorithm. Before applying this to our sample signals, let's have a look at how these methods actually work under the hood.
Mutual information
To determine an optimal value for $\tau$ we first calculate the maximum $x_\mathrm{max}$ and minimum $x_\mathrm{min}$ values of the time series, and divide the interval $[x_\mathrm{min}, x_\mathrm{max}]$ into a large number of bins. We let $p_k$ be the probability that an element of the time series is in the $k$th bin and let $p_{j,k}$ be the probability that $x_i$ is in the $j$th bin while $x_{i+\tau}$ is in the $k$th bin. Then the mutual information is defined as:
$$ I(\tau) = - \sum_{j=1}^{n_\mathrm{bins}} \sum_{k=1}^{n_\mathrm{bins}} p_{j,k}(\tau) \log \frac{p_{j,k}(\tau)}{p_j p_k} $$
The first minimum of $I(\tau)$ gives the optimal delay since there we get the most information by adding $x_{i+\tau}$.
The false nearest neighbours algorithm is based on the assumption that "unfolding" or embedding a deterministic system into successively higher dimensions is smooth. In other words, points which are close in one embedding dimension should be close in a higher one. More formally, if we have a point $p_i$ and neighbour $p_j$, we check if the normalised distance $R_i$ for the next dimension is greater than some threshold $R_\mathrm{th}$:
$$ R_i = \frac{\mid x_{i+m\tau} - x_{j+m\tau} \mid}{\lVert p_i - p_j \rVert} > R_\mathrm{th}$$
If $R_i > R_\mathrm{th}$ then we have a "false nearest neighbour" and the optimal embedding dimension is obtained by minimising the total number of such neighbours.
Let's now apply these ideas to our original signals to see what the algorithm determines as optimal choices for $M$ and $\tau$. We will allow the search to scan up to relatively large values of $(M, \tau)$ to ensure we do not get stuck in a sub-optimal minimum.
For the periodic signal, we initialise the Takens embedding as follows:
max_embedding_dimension = 30
max_time_delay = 30
stride = 5
embedder_periodic = TakensEmbedding(
parameters_type="search", time_delay=max_time_delay, dimension=max_embedding_dimension, stride=stride
)
Let's create a helper function to view the optimal values found during the search:
def fit_embedder(embedder, y, verbose=True):
y_embedded = embedder.fit_transform(y)
if verbose:
print(f"Shape of embedded time series: {y_embedded.shape}")
print(f"Optimal embedding dimension is {embedder.dimension_} and time delay is {embedder.time_delay_}")
return y_embedded
y_periodic_embedded = fit_embedder(embedder_periodic, y_periodic)
Although the resulting embedding is in a high dimensional space, we can apply principal component analysis to project down to 3-dimensions for visualisation:
pca = PCA(n_components=3)
y_periodic_embedded_pca = pca.fit_transform(y_periodic_embedded)
plot_point_cloud(y_periodic_embedded_pca)
Now for the non-periodic case we have:
embedder_nonperiodic = TakensEmbedding(
parameters_type="search", n_jobs=2, time_delay=max_time_delay, dimension=max_embedding_dimension, stride=stride,
)
y_nonperiodic_embedded = fit_embedder(embedder_nonperiodic, y_nonperiodic)
As before we can use PCA to project down to 3-dimensions for visualisation:
pca = PCA(n_components=3)
y_nonperiodic_embedded_pca = pca.fit_transform(y_nonperiodic_embedded)
plot_point_cloud(y_nonperiodic_embedded_pca)
So we have embedding point clouds whose geometry looks clearly distinct; how about the persistence digrams?
y_periodic_embedded = y_periodic_embedded[None, :, :]
y_nonperiodic_embedded = y_nonperiodic_embedded[None, :, :]
# check shapes
y_periodic_embedded.shape, y_nonperiodic_embedded.shape
The next step is to calculate the persistence diagrams associated with each point cloud:
homology_dimensions = [0, 1, 2]
periodic_persistence = VietorisRipsPersistence(homology_dimensions=homology_dimensions, n_jobs=6)
%time periodic_persistence_diagrams = periodic_persistence.fit_transform(y_periodic_embedded)
nonperiodic_persistence = VietorisRipsPersistence(homology_dimensions=homology_dimensions, n_jobs=6)
%time nonperiodic_persistence_diagrams = nonperiodic_persistence.fit_transform(y_nonperiodic_embedded)
Let's now compare the two diagrams, first for the periodic signal:
plot_diagram(periodic_persistence_diagrams[0])
and next for the non-periodic one:
plot_diagram(nonperiodic_persistence_diagrams[0])
In this case the persistence diagram for the periodic signal is essentially unchanged, but the non-periodic signal now reveals two H1 points and one H2 one - the signature of a hypertorus! It turns out that in general, the image of $SW_{M,\tau}f$ is a hypertorus.
As an application of the above ideas, let's examine how persistent homology can help detect gravitational waves in noisy signals. The following is adapted from the article by C. Bresten and J.H. Jung.
YouTubeVideo("Y3eR49ogsF0", width=600, height=400)
YouTubeVideo("QyDcTbR-kEA", width=600, height=400)
In the article, the authors create a synthetic training set as follows:
- Generate gravitational wave signals that correspond to non-spinning binary black hole mergers
- Generate a noisy time series and embed a gravitational wave signal with probability 0.5 at a random time.
The result is a set of time series
$$ s = g + \epsilon \frac{1}{R}\xi $$
where $g$ is a gravitational wave signal from the reference set, $\xi$ is Gaussian noise, $\epsilon=10^{-19}$ scales the noise amplitude to the signal, and $R \in (0.075, 0.65)$ is a parameter that controls the signal-to-noise-ratio (SNR).
As a warmup, let's generate some noisy signals with a constant signal-to-noise ratio (SNR) of 17.98. As shown in the table below, this corresponds to an $R$ value of 0.65. By picking the upper end of the interval, we can gain a sense for what is best possible performance for our time series clasifier.

DATA = Path("../data")
download_dataset('gravitational-wave-signals.npy')
R = 0.65
n_signals = 1000
noisy_signals, gw_signals, labels = make_gravitational_waves(
path_to_data=DATA, n_signals=n_signals, r_min=R, r_max=R, n_snr_values=1
)
print(f"Number of noisy signals: {len(noisy_signals)}")
print(f"Number of timesteps per series: {len(noisy_signals[0])}")
Next let's visualise the two different types of time series that we wish to classify: one that is pure noise vs. one that is composed of noise plus an embedded gravitational wave signal:
# get the index corresponding to the first pure noise time series
background_idx = np.argmin(labels)
# get the index corresponding to the first noise + gravitational wave time series
signal_idx = np.argmax(labels)
fig, (ax0, ax1) = plt.subplots(ncols=2, figsize=(12, 4), sharey=True)
ax0.plot(noisy_signals[background_idx])
ax0.set_ylabel("Amplitude")
ax0.set_xlabel("Time step")
ax0.set_title("Pure noise")
ax1.plot(noisy_signals[1])
ax1.plot(gw_signals[signal_idx])
ax1.set_xlabel("Time step")
ax1.set_title("Noise with gravitational wave signal")
plt.tight_layout()

Let's examine what the sliding window embedding of a pure gravitational wave signal looks like:
embedding_dimension = 30
embedding_time_delay = 30
stride = 5
embedder = TakensEmbedding(
parameters_type="search", n_jobs=6, time_delay=embedding_time_delay, dimension=embedding_dimension, stride=stride
)
%time y_gw_embedded = fit_embedder(embedder, gw_signals[0])
As we did in our simple examples, we can use PCA to project our high-dimensional space to 3-dimensions for visualisation:
pca = PCA(n_components=3)
y_gw_embedded_pca = pca.fit_transform(y_gw_embedded)
plot_point_cloud(y_gw_embedded_pca)
From the plot we can see that the decaying periodic signal generated by a black hole merger emerges as a spiral in the sliding window embedding space. For contrast, let's compare this to one of the pure noise time series in our sample:
embedding_dimension = 30
embedding_time_delay = 30
stride = 5
embedder = TakensEmbedding(
parameters_type="search", n_jobs=6, time_delay=embedding_time_delay, dimension=embedding_dimension, stride=stride
)
y_noise_embedded = fit_embedder(embedder, noisy_signals[background_idx])
pca = PCA(n_components=3)
y_noise_embedded_pca = pca.fit_transform(y_noise_embedded)
plot_point_cloud(y_noise_embedded_pca)
Evidently pure noise resembles a high-dimensional ball in the sliding window embedding space. Let's see if we can use persistent homology to tease apart which time series contain a gravitational wave signal versus those that don't. To do so we will adapt the strategy from the original article:
- Generate 200-dimensional sliding window embeddings of each time series
- Use PCA to reduce the sliding window embeddings to 3-dimensions
- Use the Vietoris-Rips construction to calculate persistence diagrams of $H_0$ and $H_1$ generators
- Extract feature vectors using persistence entropy
- Train a binary classifier on the topological features
We can do steps 1 and 2 in one go with the following code snippet:
embedding_dimension = 200
embedding_time_delay = 10
stride = 10
point_clouds = []
for i in progress_bar(range(len(noisy_signals))):
embedder = TakensEmbedding(
parameters_type="fixed", n_jobs=8, time_delay=embedding_time_delay, dimension=embedding_dimension, stride=stride
)
pca = PCA(n_components=3)
point_clouds.append(pca.fit_transform(fit_embedder(embedder, noisy_signals[i], verbose=False)))
point_clouds = np.asarray(point_clouds)
point_clouds.shape
For steps 3 and 4 we can chain the operations using the Pipeline class from giotto-tda:
homology_dimensions = [0, 1]
steps = [
("persistence", VietorisRipsPersistence(homology_dimensions=homology_dimensions, n_jobs=6)),
("scaling", Scaler()),
("entropy", PersistenceEntropy()),
]
topological_transfomer = Pipeline(steps)
%time X = topological_transfomer.fit_transform(point_clouds)
For the final step, let's train a simple classifier on our topological features. As usual we create training and validation sets
X_train, X_valid, y_train, y_valid = train_test_split(X, labels, test_size=0.1, random_state=42)
and then fit and evaluate our model in the same manner as previous lessons:
def print_scores(fitted_model):
res = {
"Accuracy on train:": accuracy_score(fitted_model.predict(X_train), y_train),
"ROC AUC on train:": roc_auc_score(y_train, fitted_model.predict_proba(X_train)[:, 1]),
"Accuracy on valid:": accuracy_score(fitted_model.predict(X_valid), y_valid),
"ROC AUC on valid:": roc_auc_score(y_valid, fitted_model.predict_proba(X_valid)[:, 1]),
}
if hasattr(fitted_model, "oob_score_"):
res["OOB accuracy:"] = fitted_model.oob_score_
for k, v in res.items():
print(k, round(v, 3))
rf = RandomForestClassifier(random_state=42)
rf.fit(X_train, y_train)
print_scores(rf)
plot_roc_curve(rf, X_valid, y_valid)
plt.show()

As a simple baseline this model is not too bad, although it is clearly overfitting the training set. It does better than the deep learning baseline in the article which typically fares little better than random on the raw data. However, the combination of deep learning and persistent homology is where significant performance gains are seen - we leave this as a tantalising hint for what is possible in a future course!
- Perform a hyperparameter search to improve the baseline model above
- In the original article, the authors chose an embedding dimension of 200, followed by PCA reduction to 3-dimensions. Try using the "search" capabilities to find a optimal choice of the embedding dimension and time delay - does this improve the resulting performance?
- Reduce the SNR to a lower value and repeat the above analysis - does the resulting performance match your intuition?
- Instead of using a fixed SNR value, consider sampling 10 SNR values from the range of the original article $R \in (0.075, 0.65)$. Repeat the above steps and see whether you can build a model that does better than random (this is tricky!)